Spark cluster from Open data studio Zeppelin¶
Open data studio Apache Zeppelin integrates Spark 3.x out of the box. Extra installation/initialization steps are not required.
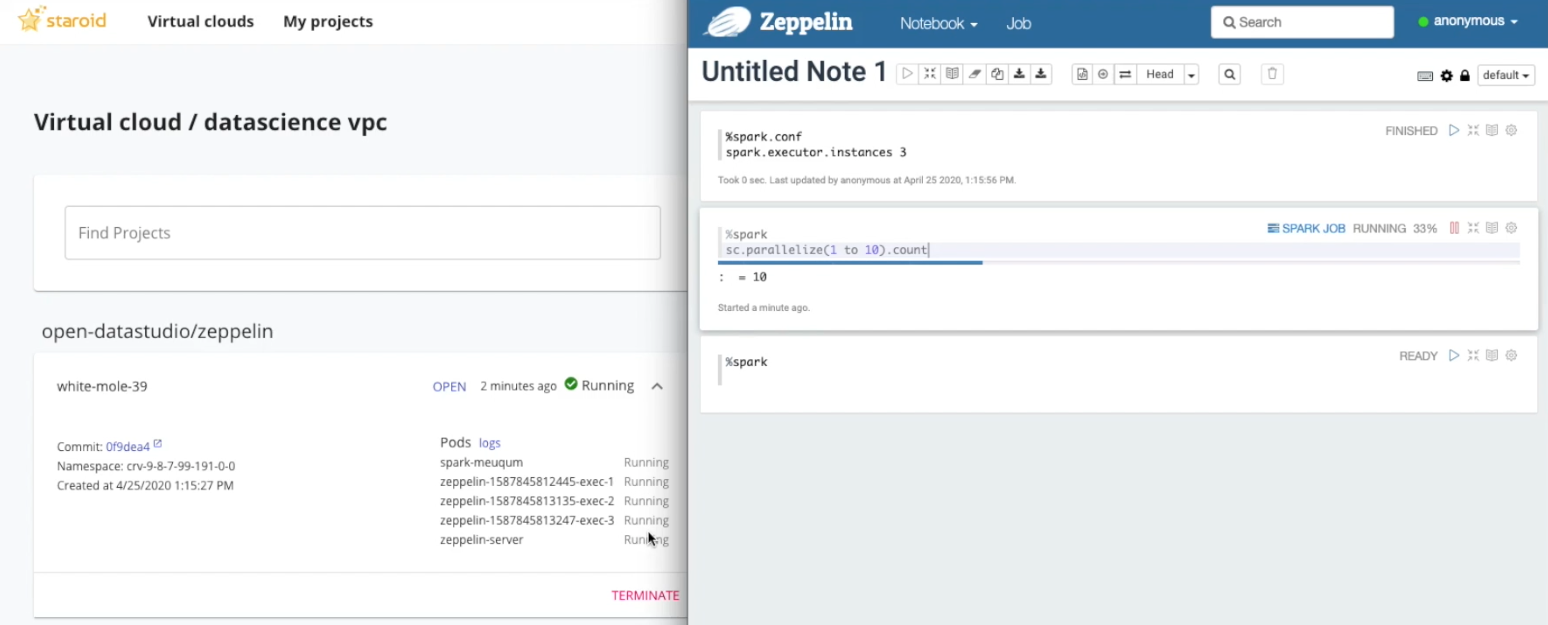
Launch and use spark interpreter. Spark cluster will be automatically created.
configure spark executors¶
%spark.conf
spark.executor.instances 3
run spark api¶
%spark
// 'sc' and 'spark' are automatically created
spark.read.json(...)
Check Apache Zeppelin for more details.