 Open Data Studio¶
Open Data Studio¶
Open data studio is a fully managed computing service on Staroid cloud, built with open source development model.
That means you can enjoy all the benefits of software as a service, without giving up ability to understand the code, contribute and improve like any other open source software.
Use cases¶
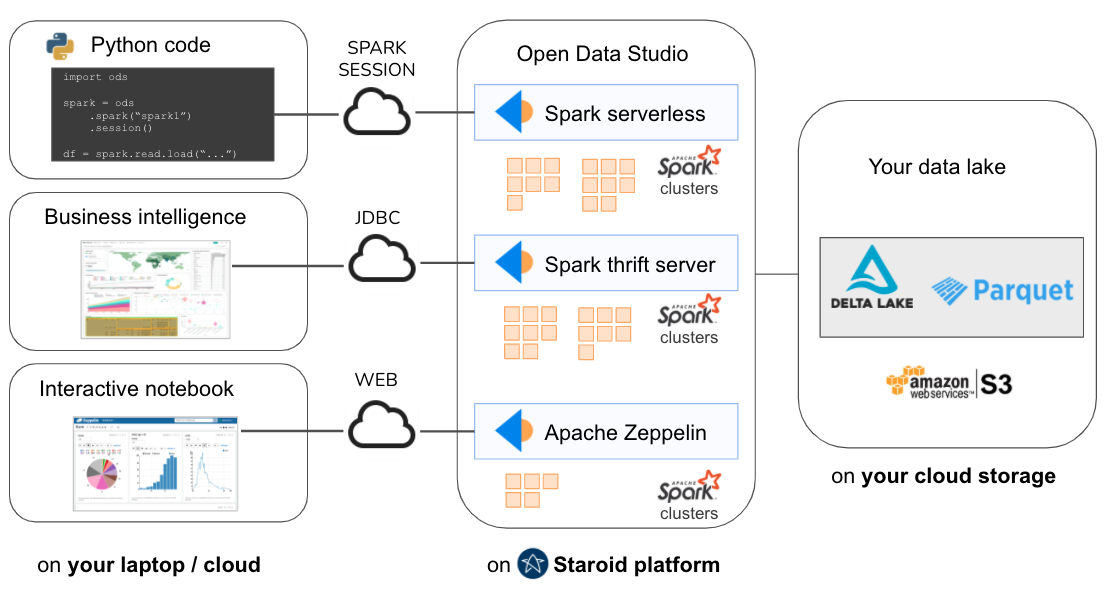
From Python shell/ide/notebook on your laptop, interactively process massive data on your data lake with Spark serverless.
Connect your BI tools via JDBC using Spark thriftserver. On-demand Spark cluster is automatically configured for you.
Visualize your data on interactive notebook using Apache Zeppelin. On-demand Spark cluster is automatically configured for you.
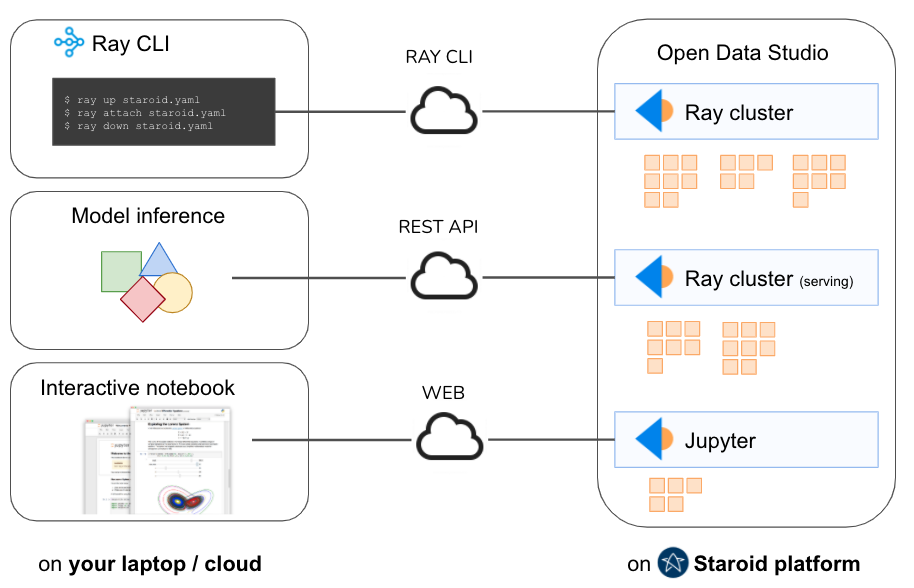
Use
ray upcommand to launch fully managed Ray cluster on the cloud.Deploy your model using Ray serve with authenticated REST API endpoint.
Launch GPU accelerated Jupyter instance on the cloud.
Technology¶
Use all the latest machine learning technology in a single place. Open data studio continues to integrate the best technologies for machine learning.
![]()
![]()
![]()
![]()
![]()
![]()
Easy of use¶
Access to the latest machine learning technology shouldn’t be more than a few clicks or a few lines of code away.
# import open data studio library
import ods
# create a spark cluster on the cloud with 3 initial workers
spark = ods.spark("my-spark", worker_num=3).session()
# run spark task
df = spark.read.load("...")
$ # install ray and staroid package
$ pip install ray staroid kubernetes
$ # switch to nightly build
$ ray install-nightly
$ # get autoscaler yaml files
$ git clone https://github.com/ray-project/ray.git
$ # spin-up cluster on the cloud and attach
$ ray up ray/python/ray/autoscaler/staroid/example-full.yaml
$ ray attach ray/python/ray/autoscaler/staroid/example-full.yaml
Fully managed¶
Save time and reduce risk. Open data studio is maintained by the committers of the open source project and industry experts on top of secure, reliable, and high performance cloud platform Staroid.
Open source¶
Open data studio is an open source project. You can easily see source code, understand how it works, and get involved. When you need, fork and get your own version of managed service!
Also, every time you launch projects, developers of the projects get funded via StarRank.
Community¶
Open data studio github - https://github.com/open-datastudio
Open data studio slack channel - Join
Issue tracker - You can find ‘issue’ menu on each projects. But if you’re not sure, create an issue here